Extract Tables from a PDF using Power Automate Desktop
By Joe Gill
Published On 23rd May 2022
I previously did a post that demonstrated how you can use Power Automate Desktop to extract text from a PDF. At the time you were not able to extract tables from a PDF. In Feb 2022 Microsoft announced that they added that capability to PAD so I thought I might give it a quick whirl. To use it simply drag the Extract Table from PDF action to the designer providing the source of the PDF and the name of the variable where the extracted tables are to be stored.
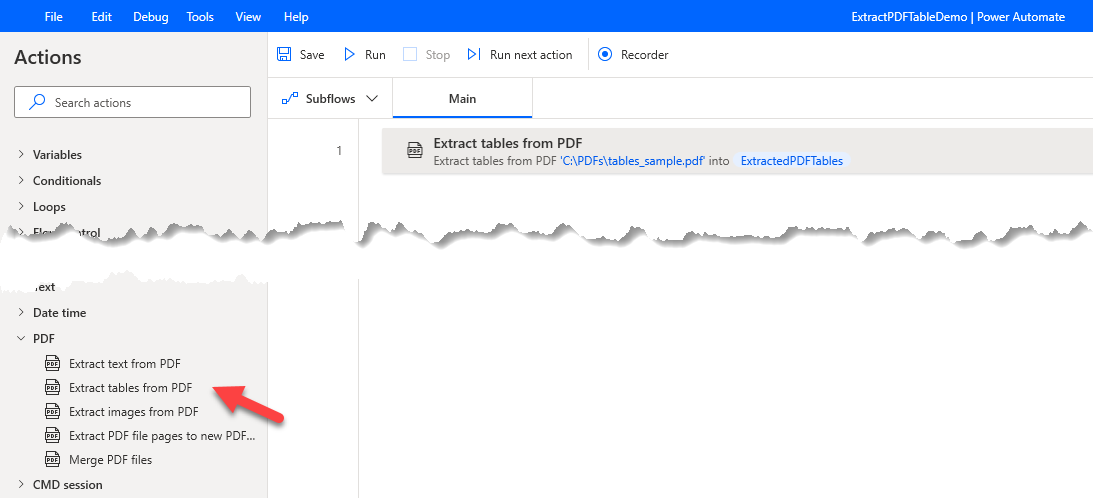
If you run this action and view the ExtractedPDFTables variable you will see that it contains a list of datatables for the tables it has found in your PDF.
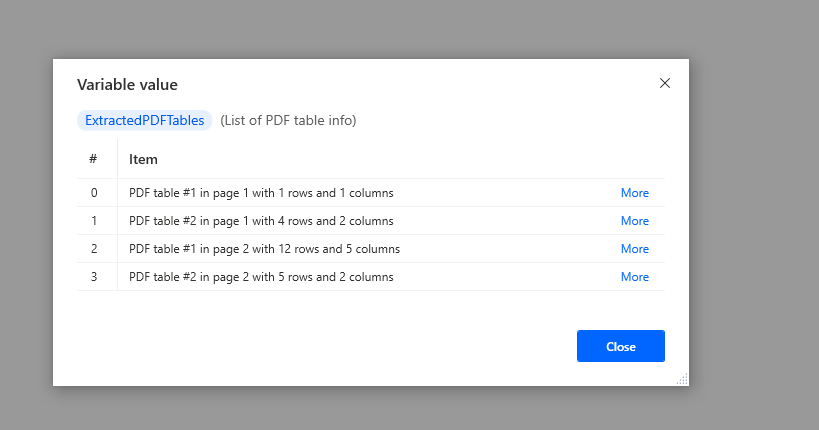
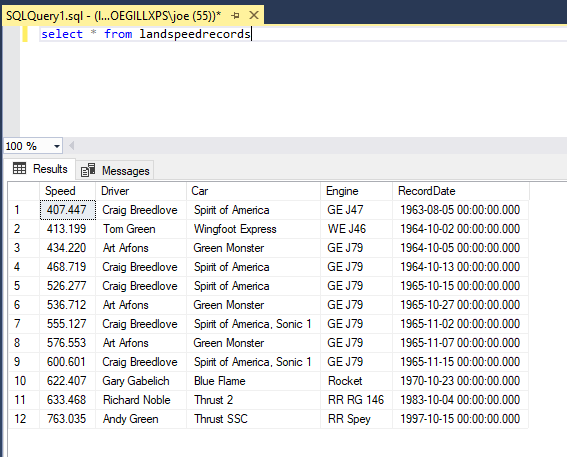
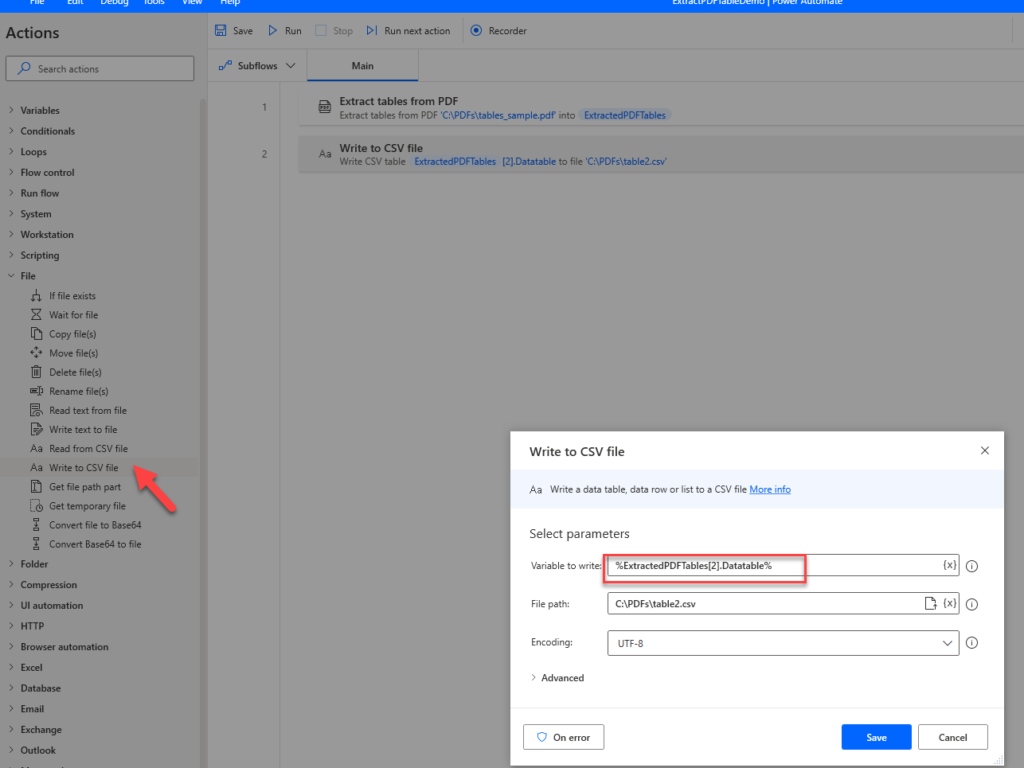
Here I added an action to write the third table in the PDF as a CSV file by using the variable %ExtractedPDFTables[2].Datatable% (remember lists start at 0, not 1)
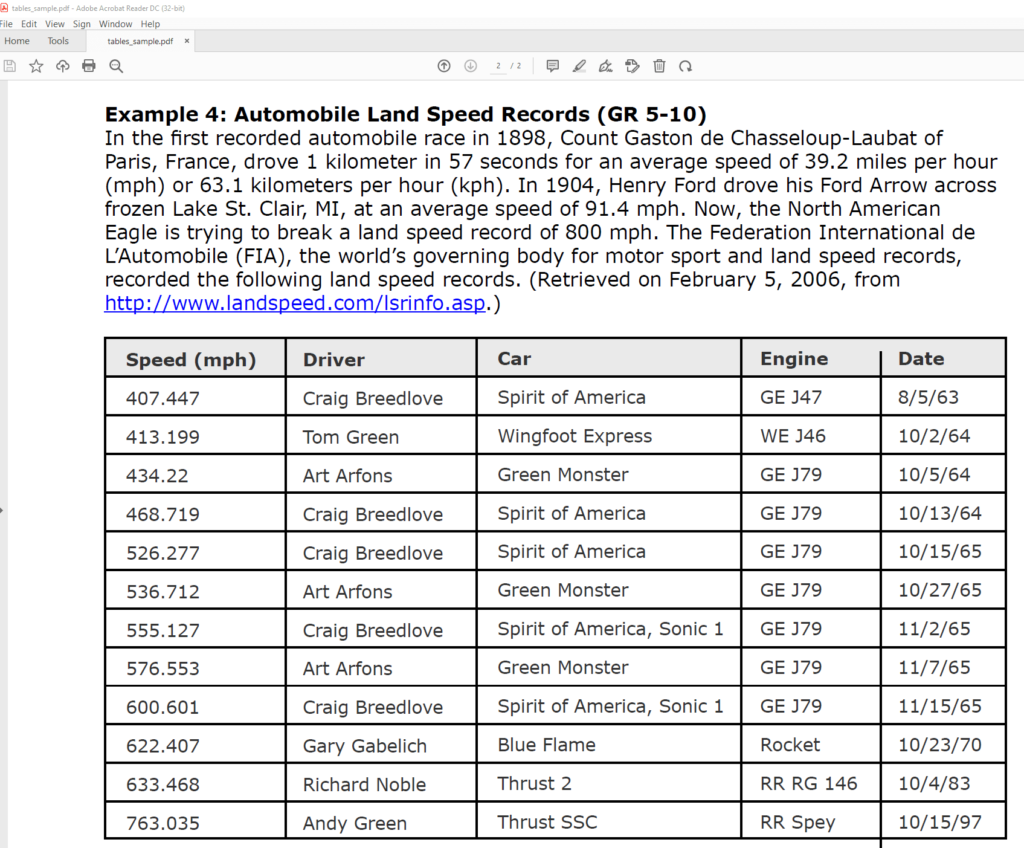
The third table in my sample PDF contains a table of land speed records.
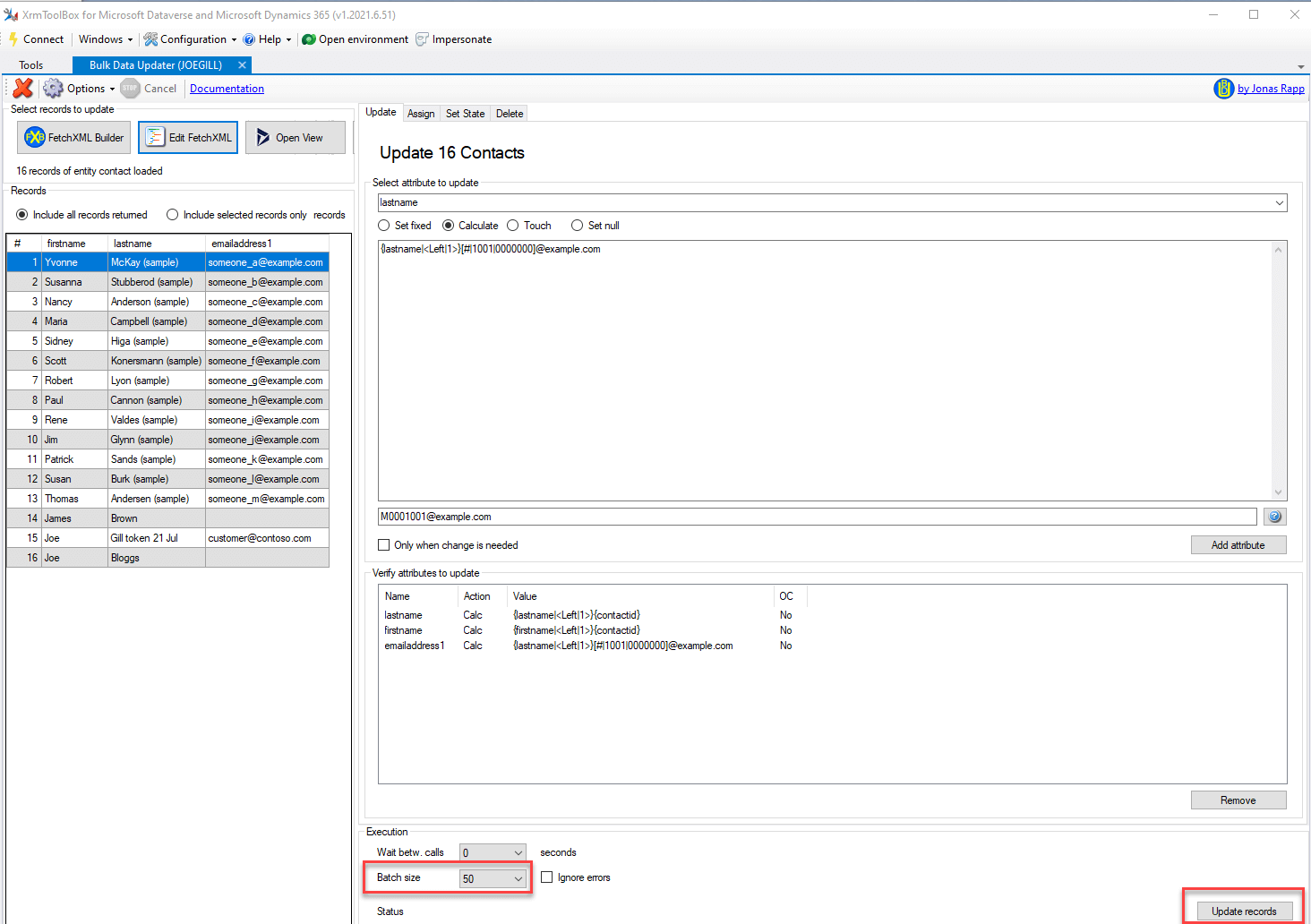
You can also use a For Each loop to iterate the rows in a data table and call actions. Here I added a database connection to my flow and within my loop added a SQL statement command to insert details of the current row into a table.
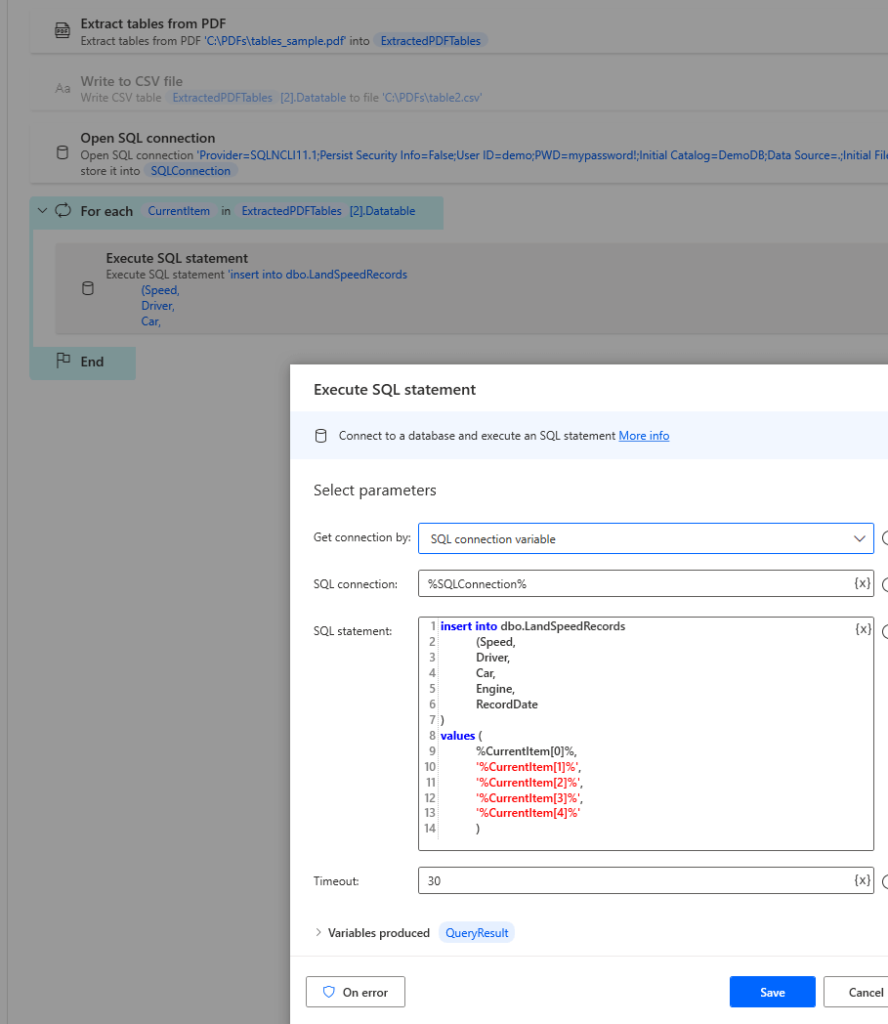
With just a few actions in my Power Automate Desktop flow I was able to extract a table of data from a PDF and insert those details into a database. The automation potential of PAD is enormous. It is also free to use on Windows so there is no reason not to give it a whirl and start automating your mundane repetitive tasks.