Azure
· Dataverse
· Power Platform
· SQL
Dataverse Metadata in Synapse
By Joe Gill
Published On 17th January 2022
Note: the Dataverse metadata is now available out of the box and so this approach is no longer relevant. I have an updated post here
When you configure Synapse Link for Dataverse it exports your Dataverse data into a Synapse data lake as CSV files. A database with external tables is created automatically in the Serverless SQL pool providing access to the data in the CSV files. You can then connect to the serverless SQL pool and use SQL to query the data. The tables in the serverless pool are in a raw state. They contain all the same columns as the Dataverse tables however there are no relationships between the tables. Nor is the Dataverse metadata available so your queries cannot return the text values for status fields or option sets (aka choice fields).
My previous post covered how to export the Dataverse options set data to Synapse Link for Dataverse so it could be queried and used in joins from the Dataverse database in Serverless SQL Pool. This post covers where to find the Dataverse metadata in Synapse and how to expose the metadata as tables. These tables can then be used in views joining to the data tables simplifying queries.
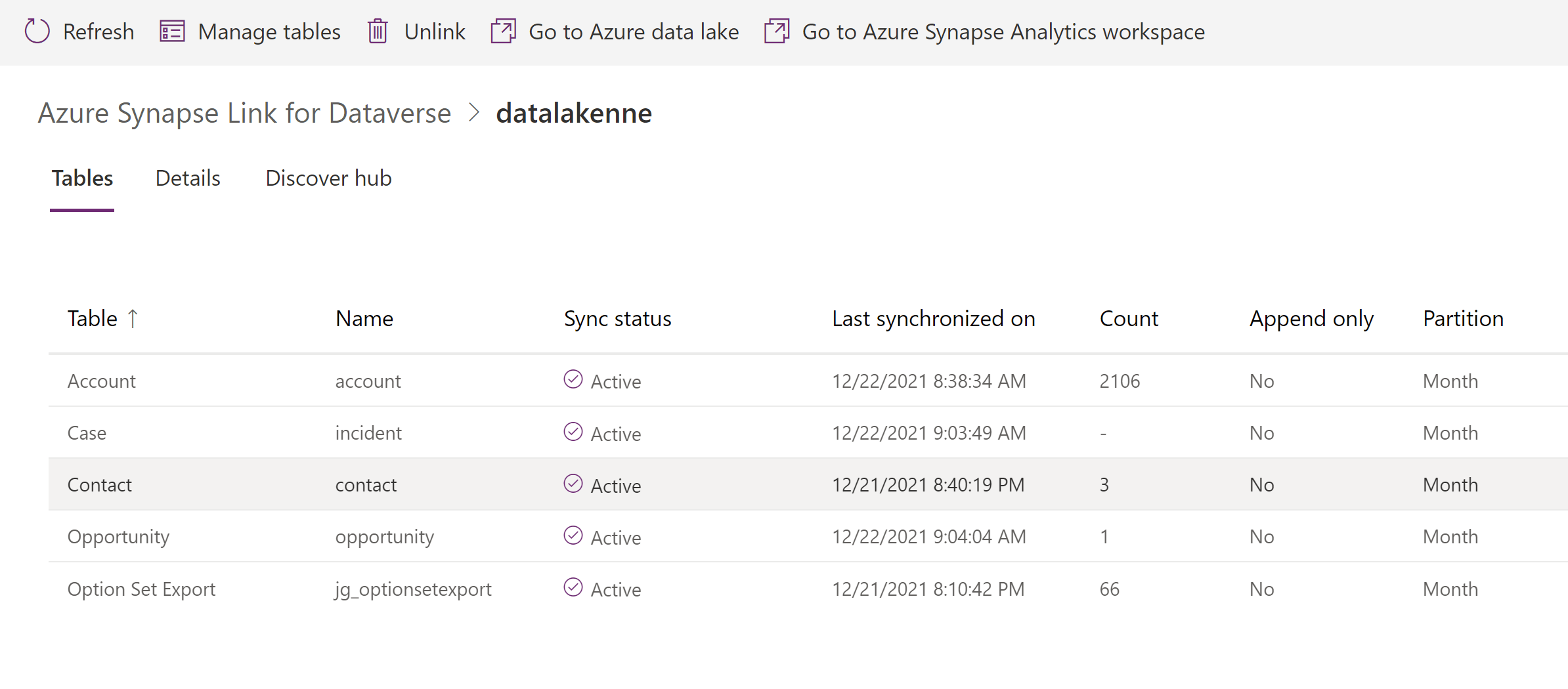
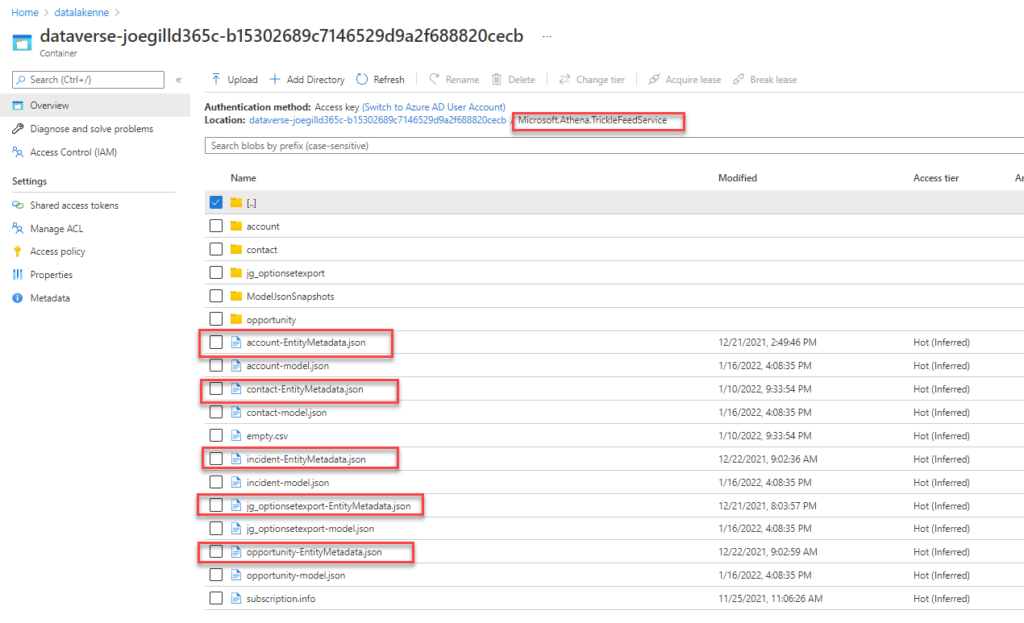
For each Dataverse table, you synchronize a metadata file in JSON format is created in the directory Microsoft.Athena.TrickleFeedService in your Data Lake storage container.
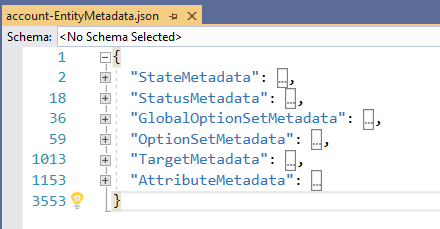
Inside each Json file are six sections for the different metadata types
By using the OpenJson function in SQL you can query the metadata JSON file and get the results as rows and columns. This example retrieves the optionset text values from the OptionSetMetadata segment of the account metadata JSON file.
select OptionSetName, OptionId, IsUserLocalizedLabel, LocalizedLabelLanguageCode, LocalizedLabel
from openrowset(bulk 'https://datalakenne.blob.core.windows.net/dataverse-joegilld365c-b15302689c7146529d9a2f688820cecb/Microsoft.Athena.TrickleFeedService/account-EntityMetadata.json',
FORMAT = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b',
rowterminator = '0x0b'
) with (doc nvarchar(max)) AS rows
cross apply openjson(doc, '$.OptionSetMetadata')
with (
OptionSetName nvarchar(4000) '$.OptionSetName',
OptionId int '$.Option',
IsUserLocalizedLabel nvarchar(4000) '$.IsUserLocalizedLabel',
LocalizedLabelLanguageCode int '$.LocalizedLabelLanguageCode',
LocalizedLabel nvarchar(4000) '$.LocalizedLabel'
) You can use this query as a Common Table Expression joining to it from the account table to display the text values for option sets.
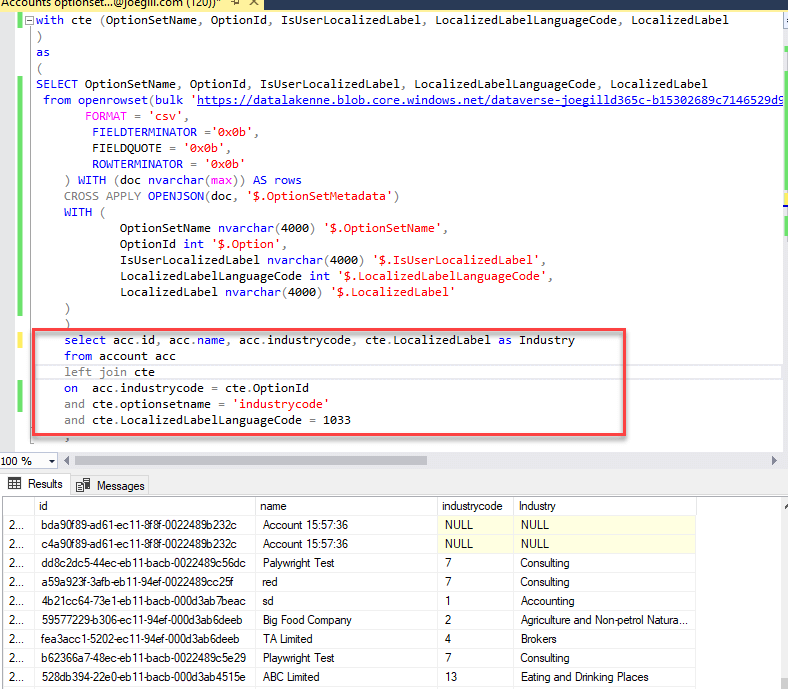
As you can imagine your query could become pretty complicated pretty quickly if you wanted to return the text values for a number of choice fields. Good practice would suggest that you create a view of your query, that you can share and reuse, so the complexity of the joins is not duplicated. Unfortunately, if you try a create a view in the database created by the Synapse Link for Dataverse you will get the error “Operation is not allowed for a replicated database”. This is because the database is replicated from an Apache Spark pool and so is read-only.
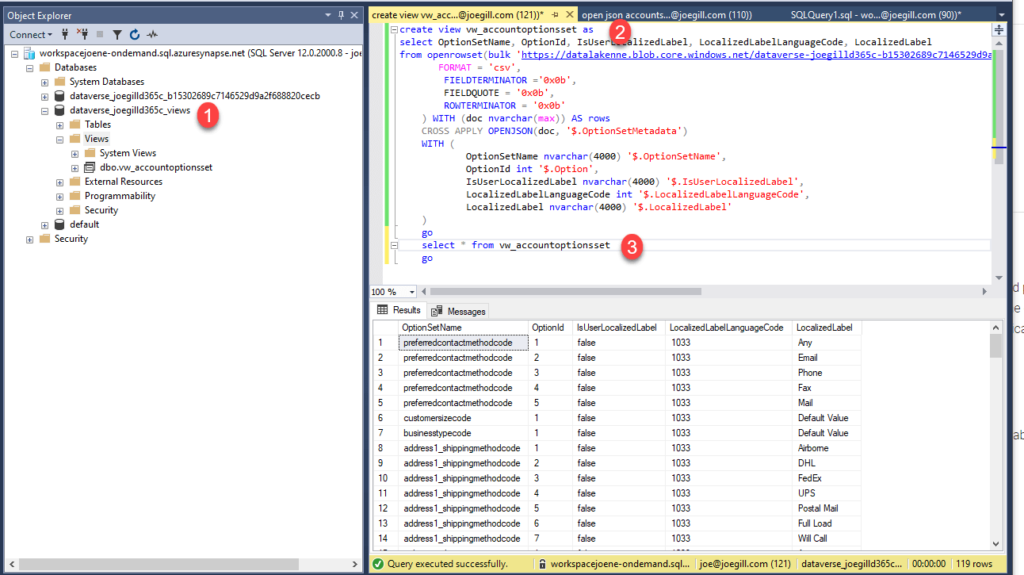
What you need do instead is to create another database in your serverless pool and create your views in this database. Here I created a new database called dataverse_joegilld365c_views and created a view to retrieve the account optionset metadata as a table from JSON metadata file.
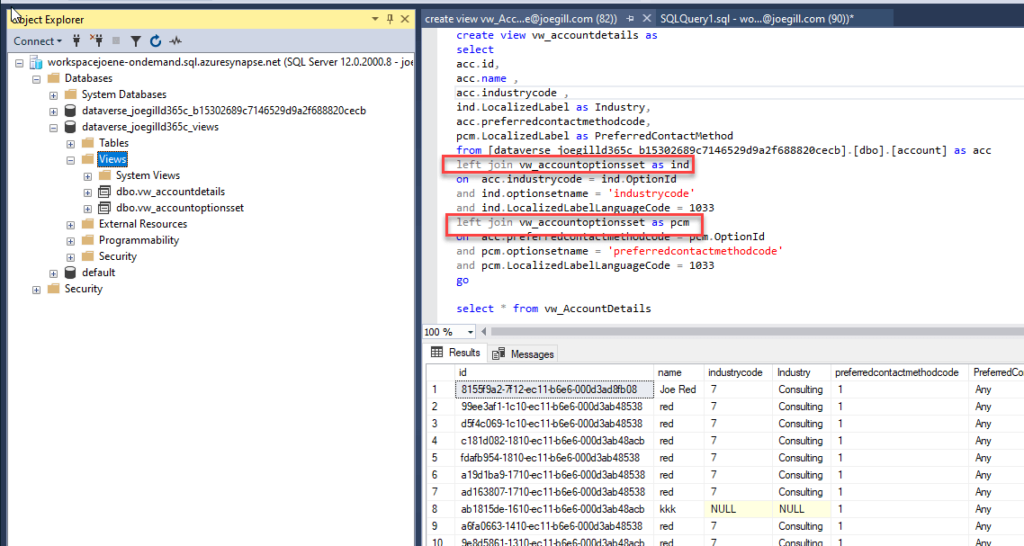
I was then able to create another view that joins from the account table in the Dataverse database with two joins to the vw_accountoptionsset view to get the text values for the industrycode and preferredcontactmethodcode fields.
Hopefully, you found this approach interesting. By creating another database in your Serverless SQL Pool and adding views to it you can hide the complexities of querying the Datavserse metadata. Your views could also include joins to other data tables to make querying the exported Dataversedata easier.