Power Platform Analytics – SQL
By Joe Gill
Published On 28th August 2023
If you have started to try out the Microsoft Power Platform self-service analytics you might have noticed some inconsistences in the formatting of Json files it creates. Most of the files are created in ndjson format but a few resembled a Json array without the [] brackets. Now all the Json files are produced in ndjson format whereby each line in the file contains a Json object.
{"name":"Doc Created","resourceId":"16bafdc4-421a-eedd-8c74-2c883ac0f144"}
{"name":"Demo Flow","resourceId":"3e3105f8-07f9-46b6-9f79-3003ad707898"}{"name":"Approve Task","resourceId":"fc782a8f-52c4-78d3-a192-9ce113339665"}If you have already configured the Data Export option in the Power Platform Admin Centre then you will need your existing Data Export config and recreate it to get all your files in ndjson format. In my previous post about I showed how you could query the Json files in the Data Lake using Power BI.
Once you configure Data Export you have access to considerable information about your Power Platform estate. If you browse your Data Lake’s storage account you will see a container called Power Platform with a folder called powerapps and a folder called powerautomate. Within these folders are a series of sub folders containing Json files the following data
- Environments
- Applications
- Application Usage
- Flows
- Flow Connection References
- Flow Usage
Once in the Data Lake you can use your choice of tools to query the data so hence the phrase of “self service analytics”. In a previous post about I showed how you could query the Json files in the Data Lake using Power BI.
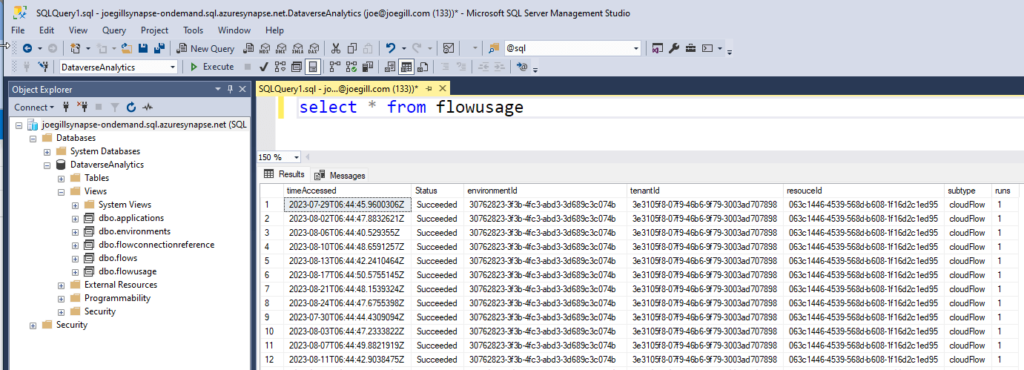
I wanted to pull the data from the Data Lake and populate some Dataverse tables using Dataflows. However I struggled to get it to work easily. Instead I decided to query the Data Lake using the OPENROWSET command in SQL Server instead. OPENROWSET is a SQL command that allows you to query data files directly without loading the data into SQL tables. It has a multitude of options for different files types and data formats. You can combine these with JSON_VALUE to read the Power Platform Analytics data in ndjson format. Here is an example of how to query the Environments files
select
json_value(doc, '$.environmentId') as [environmentId],
json_value(doc, '$.environmentName') as [environmentName]
from
openrowset(
bulk 'https://jgdataexport.blob.core.windows.net/powerplatform/powerapps/environments/*.json',
format = 'CSV',
fieldquote = '0x0b',
fieldterminator ='0x0b'
) with (doc nvarchar(max)) as rTo make is easy to consume the analytical data from the Data Lake I created a serverless database with a database view for each dataset.
create view flows as
select
json_value(doc,'$.type') as [type],
json_value(doc, '$.subType') as [subType],
json_value(doc, '$.resourceId') as [resourceId],
json_value(doc, '$.name') as [name],
json_value(doc, '$.tenantId') as [tenantId],
json_value(doc, '$.environmentId') as [environmentId],
json_value(doc, '$.resourceVersion') as [resourceVersion],
json_value(doc, '$.lifecycleState') as [lifecycleState],
json_value(doc, '$.events_created_timestamp') as [events_created_timestamp],
json_value(doc, '$.events_created_principalId') as [events_created_principalId],
json_value(doc, '$.events_modified_timestamp') as [events_modified_timestamp],
json_value(doc, '$.sharedUsers') as [sharedUsers],
json_value(doc, '$.sharedGroups') as [sharedGroups],
json_value(doc, '$.isDeleted') as [isDeleted]
from
openrowset(
bulk 'https://jgdataexport.blob.core.windows.net/powerplatform/powerautomate/Flows/*.json',
format = 'csv',
fieldquote = '0x0b',
fieldterminator ='0x0b'
) with (doc nvarchar(max)) as r
This approach allows any tool to consume the data using a SQL Server connection using T-SQL.